開始前介紹
為了讓有興趣的初學者能踏入這個領域,Dowen把以前觀念上不清楚的部分全部在pipeline中補齊許多。縱使如此也是可能有疑點的部分,如果有疑問盡量在文章下方留言,有空一定回覆:D。
CPU到GPU第一階段 - Vertex Shader的資料傳送
GPU在開始執行Vertex Shader前面,有一個動作稱為Vertex Fetching,這個動作會將我們在程式中寫的一個稱為Vertex Attribute的部分讀出來,而後傳送至GPU處。其中GPU必須由 layout (location = 0) in 來定義輸入要從GPU的哪個位置中取出,而CPU則是藉由 glVertexAttribXXX(0, data) 來將資料填入記憶體等待Vertex Fetching到GPU中layout的部分。
動手做 - CPU to GPU
首先在迴圈中加入要傳遞的資料與其對應的function,都是以 glVertexAttrib 開頭的傳遞函式。
glBindVertexArray(vertexArrayObject);
GLfloat data[] = {
(float)sin(glfwGetTime()) * 0.5f,
(float)cos(glfwGetTime()) * 0.6f,
0.0f, 0.0f
};
glVertexAttrib4fv(0, data);
glDrawArrays(GL_TRIANGLES, 0, 3);
glBindVertexArray(0);
double glfwGetTime(void) : 回傳時間參數
void glVertexAttrib[X/fm/vt]()
- X - 有1,2,3,4等數字表達。
- fm - 以i代表整數,f代表浮點數,還有其他d,s...需自行參考Spec。
- v - 代表vector,也就是傳入陣列。
結果:
小優化
知道如何傳遞資料給GPU後,我們將三角形的資料提取出來,來從外部傳入三角形Vertex,而不要直接在Shader中寫死。首先將Shader改成以下都從外部傳入的形式。但是這次不用 glVertexAttrib來做連結了,原因稍後解釋。
#version 450 core
layout (location = 0) in vec4 offset;
layout (location = 1) in vec4 vertex;
void main(void)
{
gl_Position = vertex + offset;
}
回到Code的部分,這次在迴圈外的地方改成以下的形式。
GLuint vertexArrayObject;
glGenVertexArrays(1, &vertexArrayObject); //glCreateVertexArrays(1, &vertexArrayObject); // only for 4.5
GLuint vertexBufferObject;
GLfloat vertices[] = {
0.25,-0.25,0.5,1.0,
-0.25,-0.25,0.5,1.0,
0.25,0.25,0.5,1.0
};
glBindVertexArray(vertexArrayObject);
glGenBuffers(1, &vertexBufferObject);
glBindBuffer(GL_ARRAY_BUFFER, vertexBufferObject);
glBufferData(GL_ARRAY_BUFFER, sizeof(vertices), vertices, GL_STATIC_DRAW);
glVertexAttribPointer(1, 4, GL_FLOAT, GL_FALSE, 4 * sizeof(GLfloat), (GLvoid*)0);
glEnableVertexAttribArray(1);
glBindVertexArray(0);
void glGenVertexArrays(GLsizei n, GLuint *arrays)
- 第一個參數代表陣列是產生幾個VAO物件。
- 第二個用來承接產生物件的陣列, 之前提過收到的是物件編號,也就是數字陣列。
void glBindVertexArray(GLuint array)
- 變數名稱有點不適當,這裡是代表綁定VAO物件。
void glGenBuffers(GLsizei n, GLuint * buffers)
- 與 glGenVertexArrays 的概念一樣,只是這裡是產生Buffer物件。
void glBindBuffer(GLenum target, GLuint buffer)
- 第一個是指定綁定在哪種容器上。
- 第二個是將先前產生的buffer綁定到適當的容器中,範例是綁定為VBO物件(稍後說明VBO),雖然沒有GL_BUFFER_OBJECT,但有GL_ARRAY_BUFFER,別讓名稱誤解,所以不用太針對GL_ARRAY_BUFFER這個名詞深究。
void glBufferData(GLenum target, GLsizeiptr size, const GLvoid * data, GLenum usage)
- 指定容器,會將後續參數資料填入指定容器中。
- 分配需要多少空間。
- 要傳遞的資料
- 這項有很多選擇性,只提出基本以下 GL_STREAM_DRAW, GL_STATIC_DRAW, GL_DYNAMIC_DRAW,如果data是會更動改變,使用DYNAMIC,而不會則用STATIC,若是只會更改一次的串流用途就會用STREAM。
void glVertexAttribPointer(GLuint index, GLint size, GLenum type, GLboolean normalized, GLsizei stride, const GLvoid * pointer)
- 指定要進入shader的哪個location中。
- 指定要一次讀幾個值。
- 指定值的型態。
- 指定是否要Normailize (壓縮到-1 ~ 1 的意思)。
- 指定讀完資料後,應該移動的距離。
- 指定一開始讀資料的時候,要移動的距離。
void glEnableVertexAttribArray(GLuint index)
- 開啟要使用的location,不開啟的化,Shader該location無法傳入任何值。
結果(沒變):
VBO 與 VAO
VBO的概念是將資料存到記憶體中(glBufferData),而且可以指定GPU要以什麼樣的方式讀取資料,也就是利用 glVertexAttribPointer 來指定讀取方式,而這樣的好處是什麼? 如果你的陣列之中長得像以下這樣。
GLfloat data[] = {
// position // color // normalize
0.25,-0.25,0.5,1.0,1.0f,0.0f,0.0f,0.0f,0.0f,1.0f,
-0.25,-0.25,0.5,1.0,0.0f,1.0f,0.0f,0.0f,0.0f,1.0f,
0.25,0.25,0.5,1.0,0.0f,0.0f,1.0f,0.0f,0.0f,1.0f
};
一次將許多資料都定義在一起,那麼就很輕鬆就可在送至GPU的時候做好哪筆資料應該傳入哪個location。而這裡要回到之前說的所有事情都是將Vertex Attribute傳送至GPU。只是這次利用Buffer指定格式後,Vertex Fetching會幫我們切割好後,以Vertex Attribute的格式傳入,符合之前所呼應的說明。
這裡就繪製一下VBO的概念。

這裡搭配上方的程式碼解說對照,這裡提offset,為之前沒說到的部分,假設說此時要將RGB的值,指定到Shader中location = 2的位置,這裡就要再加上 glVertexAttribPointer(2, 3, GL_FLOAT, GL_FALSE, 7 * sizeof(GLfloat), (GLvoid*)(4 * sizeof(GLfloat)) ); 也就是指定第二個location,讀取長度3,整體長度7,起始跳過4個單位長。那麼每次移動7個單位長就會移動到第二排第4個單位長,因此就成為專門將RGB給分配到location = 2的格式了。 最後別忘記啟用就好 glEnableVertexAttribArray(2) 。
好了,剛剛稍微轉了一點理解,但其實VBO實際上的概念是這樣,到 glBufferData(GL_ARRAY_BUFFER, sizeof(vertices), vertices, GL_STATIC_DRAW) 這裡就已經算結束,也就是說VBO只是配置一個記憶體的空間而已,這樣的空間或說緩衝區時常被用來連結VAO然後傳送至GPU,所以有時候比較難分清楚誰的責任是什麼,而且現代OpenGL強制使用VAO,所以你用VBO就必使用VAO。 因此這裡說明白,VBO只是個空間,VAO則是將VBO做格式定位與欄位啟動的地方,也就是說 glEnableVertexAttribArray 跟 glVertexAttribPointer 是VAO的責任。
這部分最後稍微想一下, VBO與VAO可否一對多? 多對一? 這答案都是肯定的,VAO參考多個VBO空間的值,或多個VAO參考同個空間的值,都是可以做到的事。
Tessellation
Tessellation是將複雜面(high-order primitive),而什麼是複雜面,舉例多邊形或Patch等等頂點很多的都是複雜面。而為了使用Tessellation,我們不管是三角形、矩形、多邊形,通通要以Patch的形式傳入,因此Patch是一個為了讓Tessellation知道你要使用他的一個包裹,不管裡面包的是幾邊形,總而言之就是要讓Tessellation知道是個Patch才能進行細分的動作。而這個部分主要有三個階段,第一個階段Tessellation Control Shader屬於可程式,用來接收Vertex Shader的輸出後,定義切割表面的一些參數,並且將資料傳送到下一個階段。第二個階段Tessellation Engine屬於固定流程,得到參數後,依照演算法將一個Patch詳細切割,之後將這些新的點以三角形或四邊形的形式傳入下個階段。第三個階段Tessellation Evaluation Shader屬於可程式,這個階段得到的三角形的點是屬於barycentric coordinate空間的座標,而矩形是在Bilinear interpolation所構成x,y範圍0~1的空間中。由於這部分並非初學,而且屬於選擇性實作,所以這裡看不懂可以先知道概念即可。
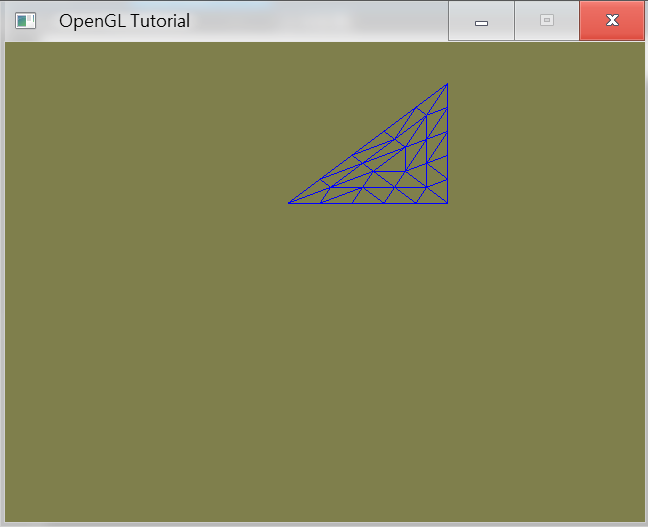
Tessellation Triangle
Geometry Shader
Geometry Shader是在要進入光柵(Rasterization)之前的階段,屬於選擇性實作的階段,因此也比較偏難需要另外講的文章,主要運作的模式是接收到一個primitive的數量後執行一次,也就是如果接收三角形則是收到三個頂點後執行一次,而這個階段能做的就是對你收到的點做些調整,舉個簡單的例子就是輸入一個三角形,這個階段可以新增一些點,修改一些點,變成輸出星星的形狀,這部分以後的文章會在探討。
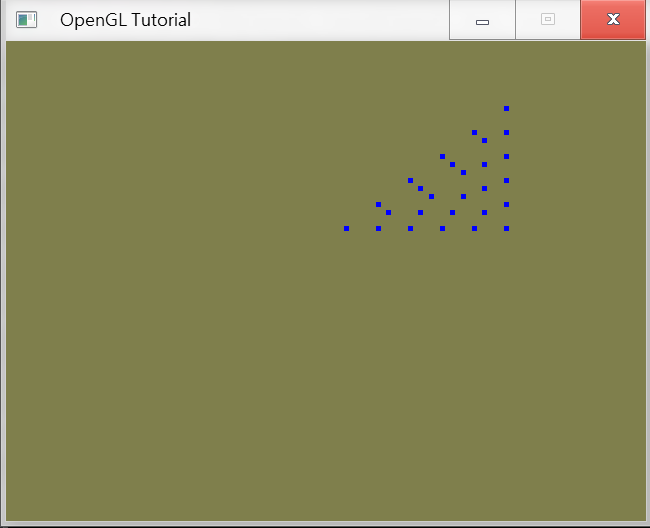
Tessellation + Geometry Triangle
Primitive Assembly, Clipping, Rasterization
這幾個階段都是屬於Fixed的部分,操作者在這些階段無法觸及內容,所以這裡就講理論上這幾個階段的功用。
Primitive Assembly
將收到的點做組裝,像是找在primitive緩衝區中找到代表直線的區塊,假設那區塊有12個連續頂點,那就會轉換成11條直線。
Clipping
這邊有一段重要的數學觀念,就是要理解Homogeneous Coordinate System跟Normalize Device Coordinate,還有透視投影(Perspective Proejction)在這之間的關係,這裡也需另外開文解釋,簡單來說我們若要了解3D空間,這個概念就不可或缺,以上幾個概念都是要在會在實作中會碰到的部分,OpengGL的這個階段在數學上是只講Homogeneous空間中的X,Y,Z除以W而已,此動作稱為Projective Division,該動作後就會到NDC空間中了。因此我們要有弄出XYZW的方法,以後的文章會提到。最後如果轉換的點超出NDC範圍就會被Clipping掉,以免浪費GPU運算速度。
Viewport Transformation
Viewport代表的是我們所定義的視窗大小,而這階段是將NDC空間那些x,y,z屬於 -1 ~ 1的座標拉伸至整個視窗上,而他對應的轉換公式如下。
以上公式根據 void glViewport(GLint x,GLint y, GLsizei width, GLsizei height); 與 void glDepthRange(GLdouble nearVal, GLdouble farVal); 來運算,通常不會去動glDepthRange,預設是 -1 ~ 1,透視投影後不會有壓縮,而公式中 , 的部分則是 $ o_x = x + \frac{weight}{2} $ 與 $ o_y = y + \frac{height}{2} $。
公式解釋: ,,是NDC空間的座標,,,是視窗空間的座標,是遠點座標,是近點座標,而前兩項是將-1 ~ 1的NDC空間拉至螢幕平面上,而最後一項則是算出螢幕中實際上代表的點深度是多少,不過這一項算完後又會被壓縮至0 ~ 1的深度給後續階段,至少我在Fragment 階段所見是這樣,而書上公式是壓縮至-1 ~ 1的公式,但書本上卻說是壓縮至 0 ~ 1,讓我思索了老半天。以下是示意圖,將x拓展至0~800, y:0~600, z:10~500。



Culling
一個正方體有其正面與反面,反面的當然就無法進行任何繪製,所以OpenGL有個機制,就是當定義頂點的時候,用逆時鐘(Conter Clockwise)的情況,會視為正面,而順時鐘會視為背面。 提醒一下,這個部分要特別開啟才會有效果(gl_Enable(GL_CULL_FACE)),如果開啟了在定義點的時候,就必須要遵守順序。
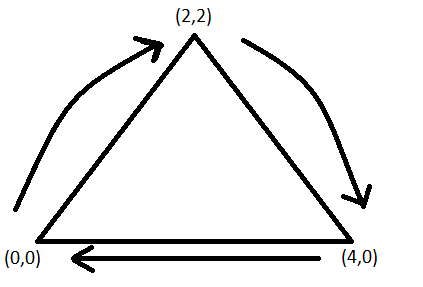
clockwise
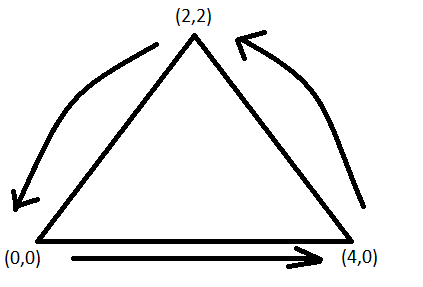
counter-clockwise
也就是說如果陣列定義的是以下這樣,將會無法顯示。
GLfloat data[] = {
// position
0.0,0.0,0.0,
2.0,2.0,0.0,
4.0,0.0,0.0
};
要改成以下這樣才可顯示。
GLfloat data[] = {
// position
2.0,2.0,0.0,
0.0,0.0,0.0,
4.0,0.0,0.0
};
其公式如下
而概念是透過向量外積找到一個垂直的向量,若a值大於0則代表該垂直向量與指向視窗的向量夾角小於90度,則OpenGL會繪製該三角形。
Rasterization
光柵化是得知哪幾個像素是要塗上顏色的地方,其中利用的是half space的方法,而Rasterizing Triangles from Michael Jones為參考的文章,如果有時間我會開篇文章解說,當初為了解整個流程這部分特別做了點筆記。
Fragment Shader
在光柵後,這個階段決定每個像素該填上的顏色為何。像是我們之前最簡單的例子像是以下這樣。
#version 450 core
out vec4 color;
void main(void)
{
color = vec4(0.0, 0.0, 1.0, 1.0);
}
很簡單的填入顏色意味著不管是哪個點,就填入藍色。而Fragment Shader 的應用很多樣,光影特效主要就是在這進行,還有各種材質的貼圖,或是畫面特效後製,優化畫面的各種技巧,都是Fragment Shader可以處理的。以下是定義三個頂點的顏色後,OpenGL利用內建的Intepolate將未定義的顏色自動內插的結果。
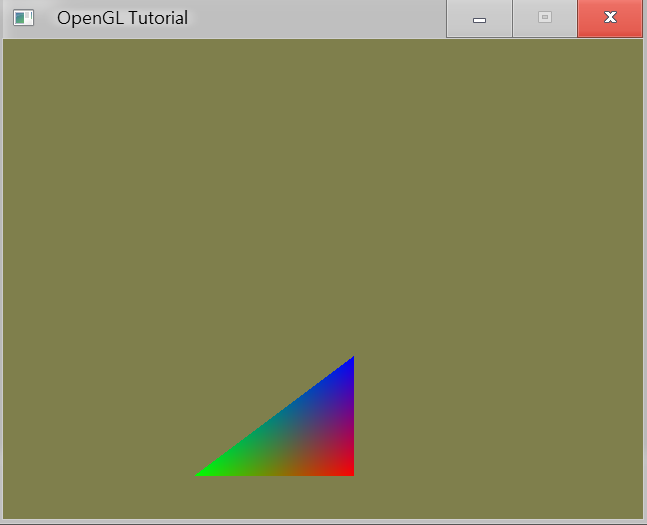
Interpolated Triangle
Last things
還有一些可以參與pipeline,而且是在Fragment Shader輸出後可以進行的東西,如Framebuffer,Scissor Test, Stencil Test,Blend,在這邊簡單介紹一下,讓讀者知道要使用相關的技術應該要利用哪個技巧。 Framebuffer : 一個儲存畫面的buffer,常用的方式是取出當前繪製的螢幕後,進行各種處理,通常拿取該畫面從頭開始跑一次pipeline。 Scissor Test : 算是很舊的技術,指定一個矩形區域,讓範圍內的像素有一些變化。 Stencil Test : 有點難說明,通常用來把一個物體的outline畫出,也就是類似選取到該物體的感覺,其作法是在每次畫出物體前先設定遮罩,藉由遮罩的AND\OR等計算,讓最後剩下的部分進行著色,例如一個畫出一個正方體,設定遮罩為1,然後畫出一個大一點的純色正方體,然後找遮罩不為1的就是所謂的外框。 Blending : 顏色的混和,簡單可做出玻璃紙特效的效果。
另外還有一個Shader無關pipeline的,是名為Compute Shader的計算著色器,可以利用GPU平行處理特性,用來處理一些計算處理的功能。
Review Pipeline
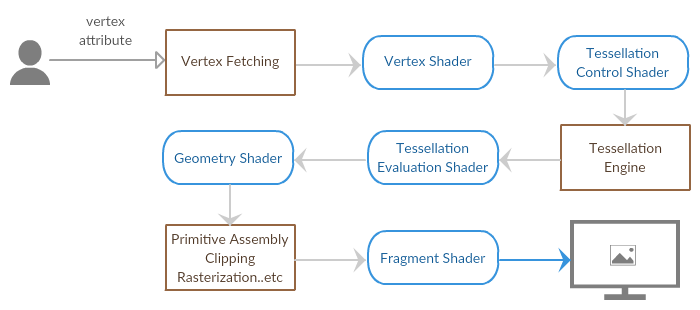
從這張圖來檢視一下每個流程的基本概念吧!框邊代表固定的流程,圓邊代表可程式的流程,而每個流程的基本概念是什麼最好能看著圖簡單解釋出來。
結語: 為了只是畫一個三角形付出了這麼多心力,是為了未來在畫面上可以擁有無限的操作可能。然而這篇可能有點說太多了,不過真的是什麼都想說,而且做圖真的不知道該用什麼來做比較好,如果有不錯的繪圖工具或線上繪圖(關於數學或流程的),請告訴我。也許以後我將這篇文章砍一半,然後將每個Shader提出來分開講,或是其他方式。